A career in data science offers a unique combination of high demand, high salaries, opportunities for growth, and the chance to work on meaningful problems. If you’re interested in mathematics, computer science, and solving real-world problems, becoming a data scientist is the way to go.
Required Skills for becoming a data scientist
Math
Mathematics is the language of the data. Data is represented through numbers, tables, matrices, series etc. Mathematical operations and equations are key to get information out of the data. But we don’t need to learn scary stuff to get started, high school math will suffice. Here is a comprehensive list of topics to get you started:
math4ml.pdf
Probability and Statistics
Preface
For years, I have been joking with my students that I would teach probability with the same level of excitement even if I were woken up in the middle of the night and asked to teach it. Years later, as a new father, I started writing this book when it became clear to me that I would not be sleeping…
Linear Algebra
Lecture Notes for Linear Algebra
6.4 Solve Linear Differential Equations
Calculus
Lecture Notes | Multivariable Calculus | Mathematics | MIT OpenCourseWare
This section provides summaries of the lectures as written by Professor Auroux to the recitation instructors.
Transform Theory (optional)
Lecture Notes | Fourier Analysis – Theory and Applications | Mathematics | MIT OpenCourseWare
This section provides the schedule of lecture topics, lecture notes for each session, and notes for the entire course as a single file.
Information theory (optional)
Lecture Notes | Information Theory | Electrical Engineering and Computer Science | MIT OpenCourseWare
This section provides the lecture notes used for the course.
Programming
Programming is key skill required to implement mathematical concepts learnt on the underlying data. Here is a list of topics and courses to get you started.
Choose a programming Language
I prefer Python, as it is widely adopted, versatile, has amazing community and is easy to learn.
How to Get Started With Python?
In this tutorial, you will learn to install and run Python on your computer. Once we do that, we will also write our first Python program.
500+ Data Structures and Algorithms Interview Questions & Practice Problems
Array
Data Mining and Analysis
So far we have looked at prerequisites for data science. Now comes the core application part. First steps into the journey of data science starts with data mining and analysis.
Data Processing
Data Analysis Using Pandas | Guide to Pandas Data Analysis
Pandas is one of the most famous data science tools and it’s definitely a game-changer for cleaning, manipulating, and data analysis.
Exploratory data analysis and visualizations
Step-by-Step Exploratory Data Analysis (EDA) using Python –
EDA is performed on the datasets to explore the data and extract all possible insights helping in model building and better decision making.
Association rule mining and clustering
#1 Introduction To Data Mining, Types Of Data |DM|
Abroad Education Channel :https://www.youtube.com/channel/UC9sgREj-cfZipx65BLiHGmwCompany Specific HR Mock Interview : A seasoned professional with over 18 y…
If you are with me so far you will be competent enough to become a data analyst, which is entry level position in the field of data science.
above course covers all machine learning algorithms you need to know as a beginner in grave detail. but for sake of saving some time I’ll list down resources for individual algorithms as well.
Linear regression is a statistical regression method used for predictive analysis and shows the relationship between the continuous variables.
Logistic regression
Logistic Regression- Supervised Learning Algorithm for Classification
This article will talk about Logistic Regression, a method for classifying the data in Machine Learning. Logistic regression is generally used where we have to classify the data into two or more classes.
Decision tree
Decision Tree Algorithm, Explained – KDnuggets
All you need to know about decision trees and how to build and optimize decision tree classifier.
Support vector machines
svm.pdf
Naive bayes
Naïve Bayes Algorithm: Everything You Need to Know – KDnuggets
Naïve Bayes is a probabilistic machine learning algorithm based on the Bayes Theorem, used in a wide variety of classification tasks. In this article, we will understand the Naïve Bayes algorithm and all essential concepts so that there is no room for doubts in understanding.
Random forest
Random Forest | Introduction to Random Forest Algorithm
Random forest is a Supervised Machine Learning Algorithm. This is an introduction to understanding random forest, its working and features.
Xgboost
An End-to-End Guide to Understand the Math behind XGBoost
Ever since its introduction in 2014, XGBoost has been lauded as the holy grail of machine learning hackathons and competitions. From predicting ad click-through rates to classifying high energy physics events, XGBoost has proved its mettle in terms of performance – and speed.
At the beginning of the textbook I used for my graduate stat theory class, the authors (George Casella and Roger Berger) explained in the…
What is LDA: Linear Discriminant Analysis for Machine Learning
Understand Linear Discriminant Analysis (LDA) in Machine Learning, Dimensionality Reduction, limitations of Logistic Regression. Learn practical approach to an LDA model.
Singular Value Decomposition | SVD in Python
Singular Value Decomposition (SVD) is a common dimensionality reduction technique in data science. Read about the common application of SVD is data science.
The why and how of nonnegative matrix factorization | the morning paper
The why and how of nonnegative matrix factorization Gillis, arXiv 2014 from: ‘Regularization, Optimization, Kernels, and Support Vector Machines.’
Clustering
What is Hierarchical Clustering? – KDnuggets
The article contains a brief introduction to various concepts related to Hierarchical clustering algorithm.
DBSCAN Clustering Algorithm in Machine Learning – KDnuggets
An introduction to the DBSCAN algorithm and its implementation in Python.
Balanced Iterative Reducing and Clustering using Hierarchies — BIRCH
The biggest challenge with clustering in real-life scenarios is the volume of the data and the consequential increase in the complexity…
K-means clusterin: The ultimate guide
K-means clustering is a widely used method for cluster analysis where the aim is to partition a set of objects into K clusters in such a way …
Gaussian Mixture Model | Brilliant Math & Science Wiki
Gaussian mixture models are a probabilistic model for representing normally distributed subpopulations within an overall population. Mixture models in general don't require knowing which subpopulation a data point belongs to, allowing the model to learn the subpopulations automatically. Since s…
Gaussian Mixture Model
Recommendation system
An In-Depth Guide to How Recommender Systems Work
Recommender systems are the brains behind product and content recommendations on websites. Here’s how they work.
Model Deployment
Data storage
How to store Data for your Data Science Process
Learn how to develop an effective data storing strategy…
Data processing
In-Depth ETL in Machine Learning Tutorial – Case Study With Neptune – neptune.ai
Most of the time, as data scientists, we think that our core value is our ability to figure out a machine learning algorithm that solves a task. In reality, model training is just the final part of a large body of work, mainly with data, that’s required just to start building a model. Before ML…
Cloud for machine learning
Best Machine Learning as a Service Platforms (MLaaS) That You Want to Check as a Data Scientist – neptune.ai
The availability of tremendous computing power in the cloud was one of the factors behind the machine learning revolution. Thus, it is not surprising that there are cloud-based services emerging, aimed at machine learning specialists. But which one to pick? Cloud-based services are not that new in f…
Experiment tracking in DVC with a few lines of Python.
Experiment tracking
Track ML experiments and models with MLflow – Azure Machine Learning
Use MLflow to log metrics and artifacts from machine learning runs
Model serving
Deploying Machine Learning Models using Flask
This tutorial will serve as an introduction on deploying Machine Learning models using Flask. We will go through various steps for building an end-to-end web application with inbuilt Machine Learning model using Flask.
How to Dockerize a Flask Application
These days, developers need to develop, ship, and run applications quicker than ever. And fortunately, there’s a tool that helps you do that – Docker. With Docker, you can now easily ship, test, and deploy your code quickly while maintaining full control over your infrastructure. It significantly re…
Conclusions
I know its a long way ahead if you are just starting your journey, but you don’t have to wait till you complete everything I listed here. There are several checkpoints where you can start your professional journey. For instance you can start your career as a data analyst once you know the core math and basic programming, and slowly keep on building your skills to move further ahead in your career.
One last tip though
You don’t rise to the level of your goals, you fall down to the level of your system.











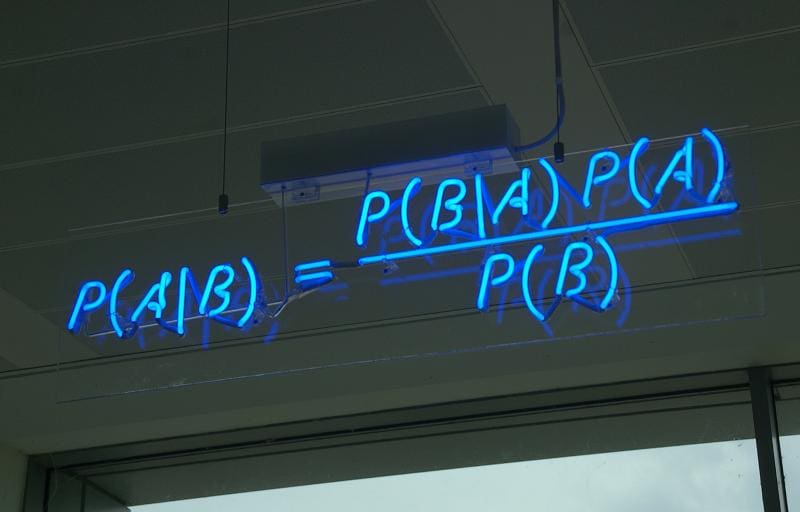












 The Ultimate Guide to Machine Learning Algorithms: From Linear Regression to Neural Networks
The Ultimate Guide to Machine Learning Algorithms: From Linear Regression to Neural Networks
 The Mind Games: How Reinforcement Learning Teaches Machines to Think Like Humans
The Mind Games: How Reinforcement Learning Teaches Machines to Think Like Humans
 The Unstoppable Force: How GBDT Ensemble Methods Conquer Machine Learning’s Toughest Battles
The Unstoppable Force: How GBDT Ensemble Methods Conquer Machine Learning’s Toughest Battles
 The Unlikely Hero: How Naive Bayes Defies Expectations in Machine Learning
The Unlikely Hero: How Naive Bayes Defies Expectations in Machine Learning
Leave a Reply